
Overview
When the development goals were laid out at AstriDevCon for Asterisk 12 way back in 2012, we had two primary missions:
- Build a new SIP channel driver to replace the venerable but aging chan_sip channel driver.
- Provide consistency in the APIs exposed by Asterisk so that it is easier to build applications on top of Asterisk.
As work progressed on the second of those two fronts – the overhaul of the existing APIs and the development of what would eventually become the Asterisk REST Interface – it became increasingly clear that substantial changes were needed in the core of Asterisk.
The crux of the problem lay in our primary reason for overhauling the APIs in the first place: Asterisk did not provide a stable model for understanding the lifetime of channels. In Asterisk 11 and prior versions, various features – such as transferring a channel, picking up a call, or redirecting a channel to a new location in the Asterisk dialplan – would result in a complex sequence of channel rename operations. Since a channel name is often used as the handle to the channel, this made it difficult for application developers to understand what was happening, particularly when something other than their application initiated the sequence.
All of the channel renames occurred due to early design decisions in the core of Asterisk. The layer of abstraction between the APIs and the core itself was rather thin, resulting in the channel manipulation details ‘leaking out’. As we analyzed the problem, it became clear that in order to provide that abstraction, the core of Asterisk needed a major upgrade. Over the course of the development of what became Asterisk 12, this upgrade occurred primarily through two major efforts:
- A new internal pub/sub message bus called Stasis
- A new Bridging Framework that maintains the state of bridged channels
This post is the first in a series that is going to focus on the second of these improvements. In particular, we’ll look at why we wrote the new Bridging Framework, the issues it solved, and the trade-offs made along the way to handle many of the interesting use cases and edge cases that Asterisk has to fulfill.
Historical Bridging
Prior to Asterisk 12, there was no object in memory that maintained the state of two or more channels in a bridge. Instead, bridging was a ‘state’ that channels happened to be in. While both channels may have dedicated threads (or a thread pool) in their channel drivers that were responsible for manipulating the media at the device level, the manipulation of media in the core of Asterisk was serviced by a single “PBX thread”, usually supplied by the inbound channel. This relatively conservative threading model served Asterisk well for a long time, particularly in resource constrained scenarios.
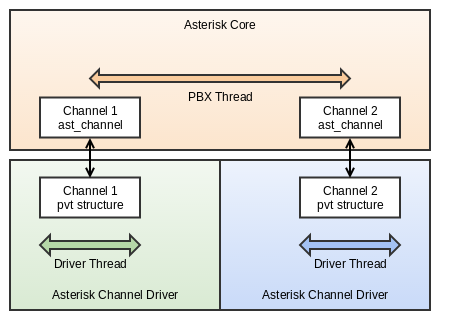 However, there are limitations with this design. In many telephony applications, two-party bridges don’t last forever. You may want to:
However, there are limitations with this design. In many telephony applications, two-party bridges don’t last forever. You may want to:
- Park one of the callers using DTMF keys
- Hit a transfer button on your phone and transfer the party to another extension
- Have a third-party web-based call control application use one of Asterisk’s APIs to move the callee to another agent in a call center
In these, and many other scenarios, we have to safely break the two-party bridge and move one of the participants out. However, because there is nothing maintaining the state of the bridge, this becomes a rather tricky operation. Traditionally, Asterisk solved this problem – for all of the above scenarios – using something called a ‘masquerade’.
What is a masquerade?
The purpose of a masquerade is to take the private data structure in the channel driver – the pvt pointer on the ast_channel structure – and re-associate it to a new ast_channel structure. That allows us to take the parts of the channel that are managing the call state – such as the SIP dialog or the ISDN channels – and tie them to a new instance of an Asterisk channel. That new channel can then be told to do something different than what the current channel is doing.
The key here is that a masquerade allows Asterisk to pull a channel out of a bridge (or anything, really) and the thread servicing it, and hand it to a new thread to have some other action be performed on the channel.
Alas, the act of doing this is tricky, as this comment in ast_do_masquerade alludes to:
/* XXX This operation is a bit odd. We're essentially putting the guts of * the clone channel into the original channel. Start by killing off the * original channel's backend. While the features are nice, which is the * reason we're keeping it, it's still awesomely weird. XXX */
“Awesomely weird” is actually a bit of an understatement.
First, we start by making a new ast_channel instance (a channel) that is going to be the destination for the pvt that we want to save. We call this channel the original , and the channel holding the pvt we want the clone . We then want to make the two channels aware of each other, such that they know that one of them is going to be masqueraded into the other. This allows code elsewhere in Asterisk – such as code responsible for destroying a channel – aware that a masquerade is going to occur. In order to do this, we have to do a very complex locking dance, where we try to safely lock both channels. This trickiness is compounded by proxy channels (chan_agent ), who may be sitting in front of the real ast_channel that we want to masquerade. What’s more, since you cannot lock two channels atomically, we also have to be careful that by the time we lock both channels, both channels are still alive and are not hungup, leading to a lot of code that looks like this:
if (ast_test_flag(ast_channel_flags(original), AST_FLAG_ZOMBIE)
|| ast_test_flag(ast_channel_flags(clonechan), AST_FLAG_ZOMBIE)) {
/* Zombies! Run! */
ast_log(LOG_WARNING,
"Can't setup masquerade. One or both channels is dead. (%s <-- %s)\n",
ast_channel_name(original), ast_channel_name(clonechan));
ast_channel_unlock(clonechan);
ast_channel_unlock(original);
return -1;
}
Assuming everything gets set up properly, both channels will be put into a state where they expect a masquerade to start.
Actually performing the masquerade involves a lot of careful steps where we record the state on the clone channel and reproduce it on the original channel. At a 100,000 ft. view, the steps to do this are:
- Remove the channels from the channels hash table. Since the names of the channels are going to change, and the hash table is keyed off the name, we have to re-insert the channels into the hash table when we are done. During this operation, we keep the hash table of channels locked to keep operations from attempting to manipulate the channels while we perform the masquerade.
- Cache any needed state on the channels, and/or stop current stateful actions from executing. This includes information about connected parties, whether or not Music on Hold is playing, or if a DTMF digit is currently being conveyed across the channel.
- We next change the names on the channels. The clone channel’s name gets a suffix appended to it of <MASQ> , while the original channel gets the clone channel’s original name (that is, without the <MASQ> suffix).
- With the channels and the channel names sufficiently mangled to indicate the masquerade is occurring, we can start swapping the state. Almost all of the channel properties are swapped – the pvt technology data structures, CDR information, alert pipes, hangup handlers, data stores, languages, parking lots, and more.
- During the swap, we indicate that the clone channel is “dead” by changing its name to the original channel’s name, suffixed with a <ZOMBIE> .
- Once all the information is swapped, we re-build any recoverable cached state onto the various channels. That include restarting Music on Hold, kicking off visible indicators, etc.
- Finally, we re-link the channels back into the channels hash table, and release the lock.
Assuming that all of the steps worked – and this is a long function (approximately 500 lines in Asterisk 11) – the original channel will now have the pvt of the clone channel, and will be in a state where it will continue as if it were the clone channel. The clone channel, on the other hand, will be in a somewhat precarious state, and generally dies after the masquerade.
What problems do masquerades present?
Masquerades present a number of challenges – both for developers maintaining and enhancing Asterisk, as well as for those building systems on top of Asterisk:
- Performing a masquerade is a lengthy process involving a large number of threads with complex locking semantics. The involvement of proxy channels (chan_agent ) and virtual channels (chan_local ) complicates the matter greatly, as additional channels beyond the channels involved in the masquerade also have to be locked. Because of this, it’s very easy for subtle bugs to get introduced that cause deadlocks.
- Because a masquerade can be triggered by any thread at any time, the threads responsible for interacting with channels have to be constantly aware that the ast_channel they are operating on may be destroyed out from under it. This necessitates locking the channel often, and – if the channel is unlocked – having to check at certain key times that the channel wasn’t masqueraded away. Masquerades thus create a ripple effect throughout the code base, and are not effectively contained by the APIs in channel.c .
- A masquerade itself is a relatively low-level operation that is used by higher level concepts, such as blind transfers, attended transfers, parking, and call pickup. A lot of boilerplate code exists in the various channel drivers, features code, and other locations to simply manage the masquerade process when these higher level functions occur. This further complicates the maintenance burden that masquerades have on the code, as API changes, bugs that are fixed, and other modifications have to be replicated carefully in a lot of places.
- While the previous points deal with the development issues of maintaining code based on masquerades, that doesn’t matter much to users or those building systems on top of Asterisk (other than when Asterisk has a bug in it). What does impact them is the process by which channels are renamed. During a masquerade, three rename events fire, and – at the end of the masquerade – the channel that has taken over the pvt now has a different name than the channel that used to own that pvt . Since a channel name is the handle by which channels are manipulated through Asterisk’s APIs, external applications have to perform a large amount of bookkeeping to keep up with what has happened in Asterisk. This has historically made developing applications on top of Asterisk more challenging than anyone would like.
- Beyond the bookkeeping requirements, external applications often had little visibility into why a masquerade occurred. Since they happen so frequently – generally, when any complex telephony action occurs – external applications would have to piece together the context from other events to understand that a blind transfer, or a call pickup, or an externally initiated redirect had just occurred.
As an example of points 4 and 5, consider the case where a channel is pulled out of a two-party bridge by an AMI Redirect action – say SIP/alice-00000002 . Asterisk would first create a new channel that is going to execute at the new dialplan location, and call it AsyncGoto/SIP/alice-00000002 . The sequence of events would look something like the following:
Event: Masquerade Privilege: call,all Clone: SIP/alice-00000002 CloneState: Up Original: AsyncGoto/SIP/SIP/alice-00000002 OriginalState: Up Event: Rename Privilege: call,all Channel: SIP/alice-00000002 Newname:SIP/alice-00000002<MASQ> Uniqueid: 1471619520.1 Event: Rename Privilege: call,all Channel: AsyncGoto/SIP/alice-00000002 Newname:SIP/alice-00000002 Uniqueid: 1471619528.2 Event: Rename Privilege: call,all Channel:SIP/alice-00000002<MASQ> Newname: AsyncGoto/SIP/alice-00000002<ZOMBIE> Uniqueid: 1471619520.1
If you were building an external application on top of Asterisk that needed to know what had happened to Alice’s channel, you would have to:
- Track the state of both channels
- Know that the AsyncGoto channel is a special kind of channel used in a Redirect
- Understand that the AsyncGoto channel is being replaced by the SIP/alice-00000002 channel
- Update the handle for the channels during each of the rename events for any future actions that may need to interact with those channels
All of that is clearly a lot of work for an application developer. For those reasons, and the other reasons enumerated previously, the community decided to focus on improving the core to provide a better API contract.
But what should Asterisk do in the core to better manage the movement of channels within it?
Enter the Bridging Framework
As noted, a large number of masquerades occur when two channels are bridged together. If we had an API that better managed the state of channels while they are bridged, we could conceivably remove all of those masquerades. That same API could then also expose a consistent view of channels and they move in and out of bridges, providing a better abstraction that Asterisk’s external facing APIs could build on top of.
Luckily, Asterisk had an API to do that. Back in the Asterisk 1.6 days, a Bridging Framework was added to Asterisk that would manage the state of channels within a bridge. However, since making everything use that framework was a lot of work, the only functionality that was ported over to it was conferencing via ConfBridge . That did, however, give us confidence that the framework itself was sound – the issue was simply in making all of Asterisk use it, as opposed to that one application.
To that extent, we decided to constrain the problem as such:
- Wherever possible, remove masquerades. If a masquerade couldn’t be removed, we’d push it deep into the core of Asterisk, effectively hiding it from Asterisk modules and more importantly, application developers.
- Provide an API that Asterisk modules can use to manipulate channels within a bridge. This API has to support both Asterisk dialplan applications, as well as interactions with channels coming through one of Asterisk’s APIs.
- Refactor the CDR, CEL, and AMI code out of the code that performs bridging. This prevents some of the complexity that we had in the previous bridging code, while making it easier to debug and maintain those interfaces.
- Finally, and most importantly, try to limit the impact of the changes. While there’s no way to maintain backwards compatibility – after all, the whole point of this exercise is to provide a different API contract – we don’t want to make this not feel like Asterisk. Asterisk has been wildly successful; we want to improve it, not try to create something completely brand new.
In the next post in this series, we’ll go over the initial implementation of the Bridging Framework, its core concepts, and how we began to apply that to the various use cases that Asterisk required us to meet.
